Que ce soit une application logicielle, un site web de gestion, un fichier Excel ou encore une application mobile, il est important de poser les bases avant de procéder au développement. Sans une bonne fondation, c'est comme essayer de construire une maison dont les fondations ne sont pas droites et assez solides. Lors de la construction, les charpentiers vont devoir corriger les problèmes en effectuant des travaux moins standards, ce qui va engendrer des coûts. Lors du vieillissement du bâtiment la même chose se produira. Il y a un plus grand risque d'avoir des bris et donc des travaux supplémentaires.
Pour le développement d'une application, c'est la même chose. Il faut poser les bonnes bases pour avoir un développement durable et efficace. Les bonnes bases se posent avec l'analyse des données à traiter et la structuration de celles-ci ! Et oui, la structure des données !
Comment savoir si les données sont bien structurées ?
La structuration des données est importante parce que l'application sera bâtie autour de cette structure. Une mauvaise structure aura pour effet de complexifier le traitement dans certains cas, mais aussi d'amener une perte de données. De plus, le changement de structure lorsque l'application fonctionne et a des données est plus complexe parce qu'il faut remanier les données existantes et reprogrammer les interfaces et le code qui traite ces données.
Un exemple d'une mauvaise structuration
Voici un exemple d'une mauvaise structuration et des effets négatifs que cela apporte. Prenons un exemple simple, un mélangeur industriel qui mélange des recettes de gâteaux. Le mélangeur a une capacité de 1000 kg. Pour simplifier, nous allons utiliser le minimum de données.
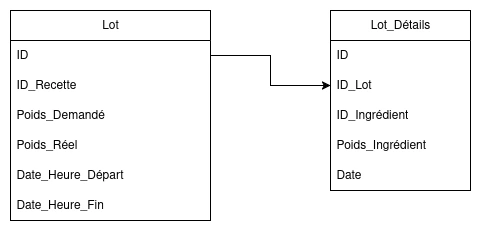
Dans l'image suivante, vous retrouverez deux tables qui se nomment "Lot" et "Lot_Détails". Les tables sont des "groupes" qui permettent d'organiser les données. Dans la table "Lot", vous retrouverez les informations suivantes (ID, ID_Recette, Poids_Demandé, Poids_Réel, Date_Heure_Départ, Date_Heure_Fin). Pour la table "Lot_Détails", vous retrouverez les informations (ID, ID_Lot, ID_Ingrédient, Poids_Ingrédient, Date_Heure) "ID" est une abréviation d'identifiant. Donc, dans la table "Lot_Détails", on retrouve "ID_Lot" qui est l'identifiant du lot ce qui permet de savoir quelle information est associée avec quel lot.
Maintenant qu'on a posé les bases de la structure et qu'on comprend comment les données sont organisées entre elles, regardons ensemble un cas pratique qui est problématique avec la structure.
L'utilisateur qui produit les différentes recettes avec le mélangeur a besoin de faire une recette de 5000 kg, or le mélangeur permet seulement de faire des mélanges de 1000 kg. Il est donc nécessaire que l'application sépare le lot en 5 mélanges. Dans la table "lot", on retrouvera l'identification du lot, l'identification de la recette demandée par l'utilisateur, le poids demandé, le poids réel et la date et l'heure du début de la production et de la fin de la production. Jusqu'ici tout est correct. Pour ce qui est de la table "Lot_Détails" on retrouvera l'identifiant du lot avec les ingrédients, le poids de chaque ingrédient qui a été inséré ainsi que la date et l'heure de l'insertion.
Dans notre situation, la structure est dite fonctionnelle puisqu'elle permet d'enregistrer les données importantes et de retracer les lots complets, mais elle ne permet pas de retracer efficacement les mélanges d'un lot. Il est seulement possible de retracer les mélanges avec les dates d'incorporation des ingrédients. Donc, exemple que le client veut avoir une interface dans son logiciel qui donne le détail des mélanges d'un lot qui ont été faits, il faudrait programmer une logique qui irait déduire les mélanges faits à partir des dates des ingrédients insérés. Bien que cela soit réalisable, il faut trouver un temps minimum entre l'insertion des ingrédients des différents mélanges pour en déduire les mélanges faits. Bien que cela fonctionne, il n'est pas garanti que la valeur minimum est bonne en tout temps. Il y a donc un risque d'erreur.
L'autre solution possible serait de retourner voir les ingrédients de la recette et déduire les mélanges d'un lot par les ingrédients, mais pour cela il faut être certains que la recette n'a pas changé dans le temps et donc si celle-ci a changé cela va fausser les données.
On vient de voir que la structure précédente cause une problématique lorsqu'on veut retracer précisément les mélanges d'un lot. Pour que ça fonctionne, le programmeur doit programmer une logique qui n'est pas fiable à 100%. Aussi, plus de travail doit être fait ce qui amène un coût supplémentaire pour le client.
La solution ?
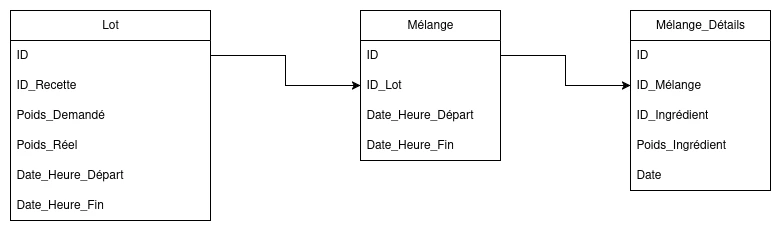
La solution à ce problème se trouve dans la structuration des données. Il suffit d'ajouter une table "Mélange" et de renommer la table "Lot_Détails" en "Mélange_Détails". La nouvelle table "Mélange" servira à enregistrer chaque mélange fait. Chaque ligne de cette table sera associée à un lot et aux ingrédients insérés pour le mélange. Pour retrouver les détails des mélanges d'un lot, il suffit simplement d'adapter la requête faite à la base de données pour aller chercher les données dans la nouvelle table, puis de les afficher. Pas besoin de programmer une logique pour déduire les mélanges, et la solution est fiable à 100% !
En résumé
Notre mise en situation était un cas simple, mais qui démontrait bien comment une mauvaise structure peut apporter du travail supplémentaire et des problèmes de fiabilité dans les données. Dans une application de taille plus importante, plusieurs erreurs comme celle-ci peuvent rapidement amener à un désastre et des coûts supplémentaires.
C'est pourquoi le travail d'un analyste consiste à comprendre les données pour bien les structurer dans l'application. Il doit aussi être en mesure de préparer la structure pour de futurs demandes du client pour que celles-ci soient faciles à effectuer sans demander trop d'investissement de la part du client.





